2025 年 半导体市场在 AI需求爆发与全产业链复苏的双重推动下,呈现出强劲的增长态势。以 EDA/IP先进方法学、先进工艺、算力芯片、端侧AI、精准控制、高端 模拟、高速互联、新型存储、先进封装等为代表的技术创新,和以AI数据 中心、具身智能、 新能源汽车、工业智能、卫星 通信、AI眼镜等为代表的新兴应用,开启新一轮的技术和应用革命。过去的一年,半导体助力夯实数字经济高质量发展的全新底座,新的一年,半导体行业又将如何推动端云协同、普惠智能的普及之路呢。
最近,由电子发烧友网策划的“2026半导体产业展望”专题正式发布。电子发烧友网已经连续数年策划并推出“半导体产业展望”系列专题,每次一经上线都反响热烈、好评如潮。这里汇聚了半导体高管们对往年发展的回顾与总结,以及对新年市场机会和形势的前瞻预测。他们的睿智和洞察给了产业界莫大的参考和启发。今年来自国内外的半导体创新领袖企业高管们又带来哪些前瞻观点?此次,电子发烧友网特别采访了奕行智能,以下是他对2026年半导体产业的分析与展望。
2025年,全球 人工智能产业蓬勃发展,芯片行业的竞争格局也在不断重构。
作为智算底座的核心产品,AI算力芯片加速演进。以Google TPU(张量处理单元)及Gemini 3.0大模型的成功为代表,领域专用架构(DSA)凭借其在特定计算任务中的性能和TCO(总体拥有成本)等优势迎来爆发。
另一方面,通用 GPU(GPGPU)也融入了 Tensor Core(张量核心)、TMA(张量内存加速器)等DSA类设计。12月, 英伟达以200亿美元获得AI芯片独角兽Groq的推理技术授权,把Groq LPU(语言处理单元)纳入产品版图的同时,也将前谷歌TPU创始成员招入麾下,体现出GPU巨头在多元化技术架构上的战略布局。
未来的计算范式是否会走向极致的专用化?
随着算力与Token消耗的爆炸式增长,对于“每Token成本”与能效比的关注,无疑会继续推动DSA领域专用架构的发展。同时,AI软件、模型、 算法等前所未有的创新速度,不断发展的智能化应用,仍需要AI算力芯片具备一定的通用性——可定制、可扩展,具有良好的可 编程性和兼容性,以适应当下和未来AI场景的需求。
新的一年,软件和模型算法生态创新,将继续驱动计算芯片 向专用与通用架构融合。
RISC-V:平衡通用性与专用性的AI计算理想底座
RISC-V开放、精简,指令集本身图灵完备,保障了通用计算能力,同时其模块化设计允许厂商在标准指令集基础上,自由拓展专用AI计算指令(如张量扩展),实现定制化加速。上述特点,使RISC-V成为平衡通用性与专用性的AI计算理想底座。
在AI计算中,尽管矩阵计算近年来备受瞩目,但AI算法中的许多关键步骤(如激活函数、归一化)仍依赖向量运算。作为RISC-V生态的关键组件, RISC-V向量扩展(RVV)原生支持复杂向量计算,它支持多种数据类型的混合精度计算,可扩展的向量长度以及宽度扩展和压缩运算,被视为AI计算的支柱之一。
更重要的是, RISC-V支持自主构建AI算力基石。传统的封闭式架构,因其固定指令集架构和许可模式限制了针对特定工作负载的深度定制,且可能受政策变化影响。RISC-V拥有开放标准、零授权成本的特点,赋能芯片厂商更加自由地进行创新,在保持技术和商业自主性的同时,共享全球范围内的生态创新成果。目前,GCC/LLVM等主流编译器已支持RISC-V,主流AI框架正在积极适配。
从Google TPU引入RISC-V 处理器,到不久前Meta、 高通收购高性能RISC-V初创企业,无不为RISC-V + AI方向的市场潜力背书。据RISC-V国际基金会数据,2024年全球基于RISC-V指令集的芯片出货量已突破百亿颗,其中30%应用于AI加速场景,相信未来这一数字还将持续上升。
奕行智能:锚定RISC-V AI赛道,引入VISA与Tile级动态调度架构创新
奕行智能选择“RISC-V + RVV”来构建AI芯片架构,并引入独创的虚拟指令(VISA)技术、基于Tile级动态调度架构等,打造满足客户极致TCO(总体拥有成本)需求的AI计算芯片,提供高效、灵活、可扩展的AI计算加速解决方案。
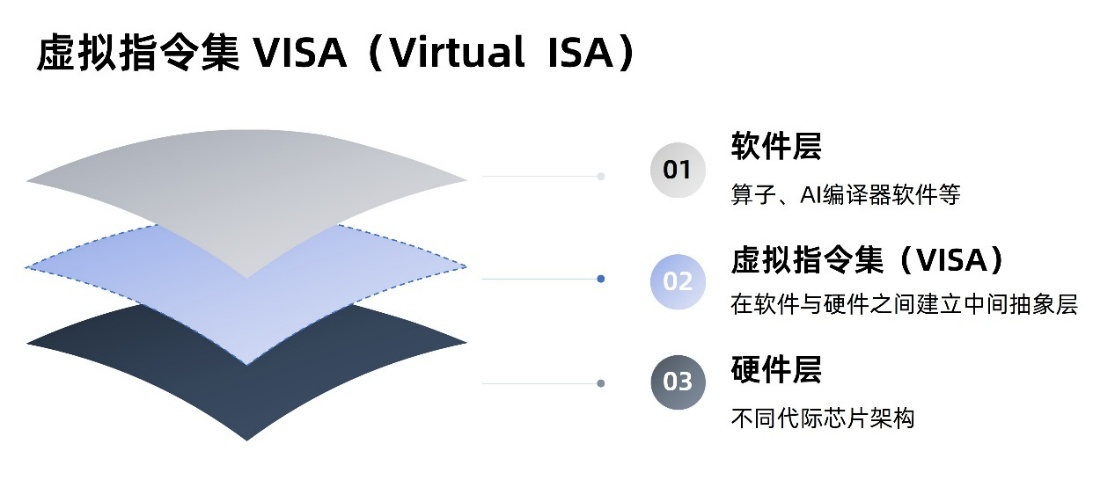
独创的虚拟指令(VISA)技术:在硬件层面通过RVV的向量定制指令方式提供硬件扩展能力,同时VISA提供了软件层面的向量计算扩展——将细粒度指令封装并且优化成具备Tile语义的微内核。 这样一套软硬扩展的方案,使得架构在模型数量多变化快的基础上,解决了通用与效率的兼顾。
在软件与硬件之间,VISA建立中间抽象层,让上层的算子及AI编译器软件建立在此抽象之上,隔离硬件变化对上层软件带来的冲击。针对AI编译过程中从高层抽象到底层硬件指令的陡降问题,VISA通过使用软流水、循环展开等方式进行优化,编译器以及算子实现只需关注到VISA层级,降低实现难度,提供额外的性能优化空间。
在软件方面,以Triton、TileLang为代表的 Python化算子开发和基于Tile(数据块)编程的创新生态正在快速崛起,最近的CUDA更新中也推出了CuTile编程模型。
奕行智能的软件栈紧扣这一趋势。AI编译器不仅深度适配PyTorch生态、支持 TensorFlow、JAX、ONNX等主流 机器学习框架,且已经实现对于Triton的功能性支持,正通过扩展算子编程方式、生态共建、引入AI工具,进一步提升支持能力。
独家打造的Tile级动态调度架构,由Tile级虚拟指令集(VISA)、智能VISA编译器 ACE和VISA调度器(Scheduler)组成,有效解决跨代兼容、动态硬件行为适配、静态优化天花板等核心挑战,从而更充分地发挥硬件潜能并快速实现上层生态对接。
2026年,奕行智能将继续深耕RISC-V AI算力芯片领域,致力于成为行业的技术引领者,持续推动产品规模化落地,并携手生态伙伴共建开放共赢的智算新生态。
推荐阅读:
时间跨度长达13年 A股又一百亿级财务造假案曝光!5家上市公司造假细节浮出水面







